随着最近 deepseek 的爆火,很多大佬都开始了在本地进行 deepseek 的部署操作,并且离线也可以使用,这里的话我就一步一步带你们部署本地的 deepseek, 说实话这个人工智能的实力不亚于 open ai 的 gpt
安装 ollama
- 我们需要先安装 ollama,安装地址 ollama, 我们直接点击下载,我们在下载的时候尽量使用我们的谷歌浏览器,有魔法的最好带上魔法,不然安装的时候可能会出问题,如果你有我的好友的话可以私信我把 exe 文件发你
- 选择对应的版本进行下载,这里我的实例是 Windows
- 这里我们就显示下载好了,软件还怪大的,745MB
- 我们找到我们下载那好的 exe 文件双击进行安装

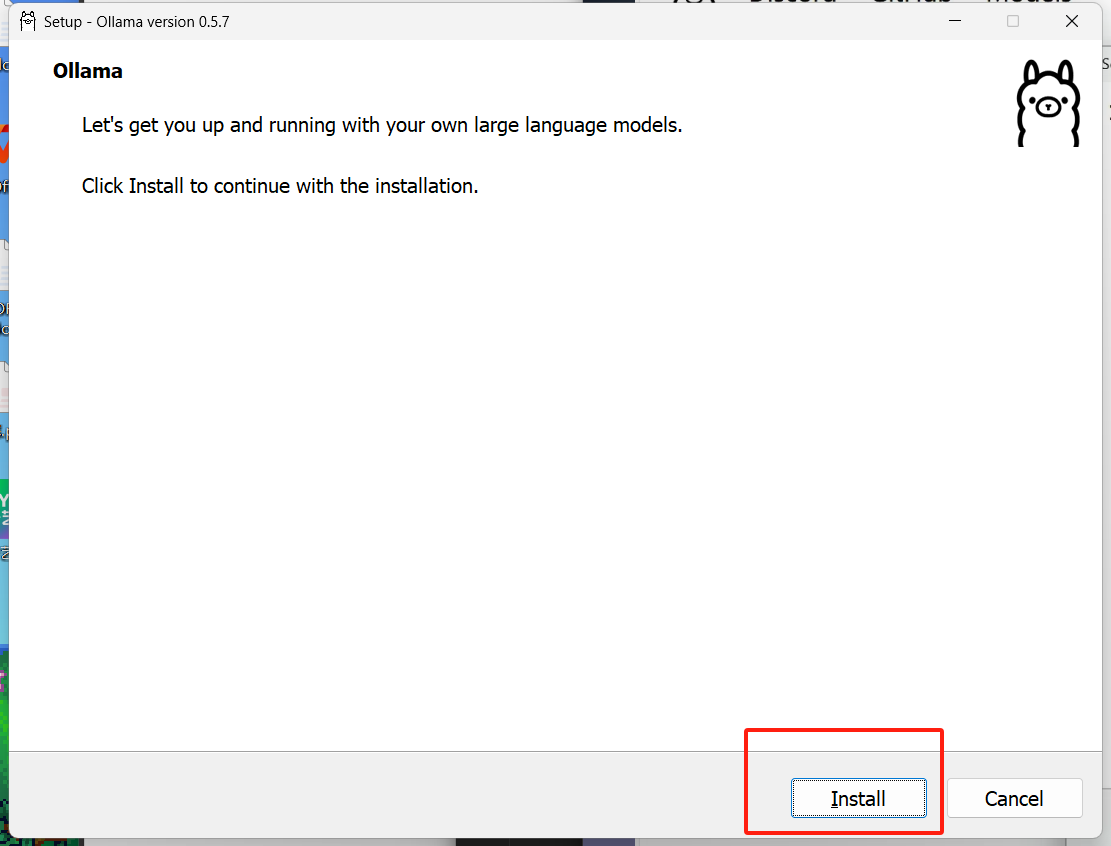
- 直接点击这里的 install 进行软件的安装,等待几分钟即可
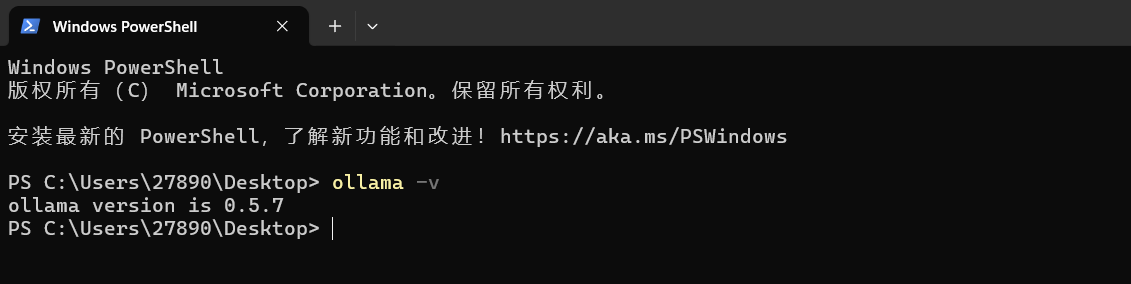
- 如何判断我们的 ollama 如何安装完毕呢?我们直接 win+R 输入 cmd 调出命令行进入到命令模式,输入命令
ollama -v查看是否安装成功,输入完命令出现了版本号的话就说明你安装成功了
部署 DeepSeek R1 模型
接下来我们进行部署 DeepSeek R1 模型的操作
- 我们依旧打开 Ollama 的官网, 然后我们可以看见我们左上角有一个 Models 的选项,我们点击下
- 然后第一个就是 deepseek R1 的模型,我们再次进行点击操作

- 这里的话有很多模型,我们可以根据自己电脑的显卡配置进行选择相应的版本
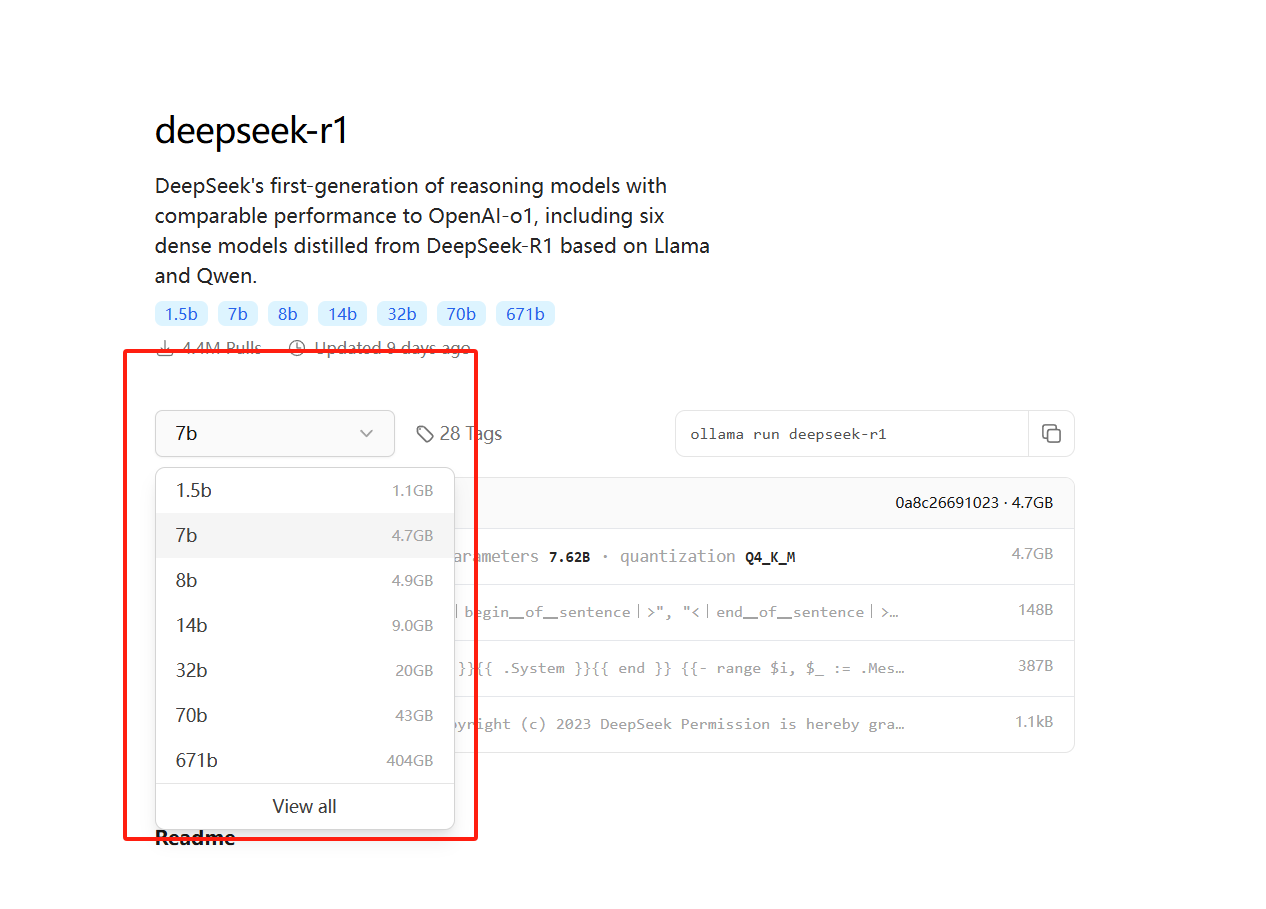
- 下面是我总结的一个模型参数大小对应的显卡配置,为了更加方便的给大家进行演示操作,这里的话我选择这个 7B 模型
| 模型 | 参数 (B) | VRAM 要求 (GB) | 推荐 GPU |
|---|---|---|---|
| DeepSeek - R1 - Zero | 671B | ~1,342 GB | 多 GPU 配置 (例如,NVIDIA A100 80GB x16) |
| DeepSeek - R1 | 671B | ~1,342 GB | 多 GPU 配置 (例如,NVIDIA A100 80GB x16) |
| DeepSeek - R1 - Distill - Qwen 1.5B | 1.5B | ~0.75 GB | NVIDIA RTX 3060 12GB 或更高 |
| DeepSeek - R1 - Distill - Qwen 7B | 7B | ~3.5 GB | NVIDIA RTX 3060 12GB 或更高 |
| DeepSeek - R1 - Distill - Llama 8B | 8B | ~4 GB | NVIDIA RTX 3060 12GB 或更高 |
| DeepSeek - R1 - Distill - Qwen 14B | 14B | ~7 GB | NVIDIA RTX 3060 12GB 或更高 |
| DeepSeek - R1 - Distill - Qwen 32B | 32B | ~16 GB | NVIDIA RTX 4090 24GB |
| DeepSeek - R1 - Distill - Llama 70B | 70B | ~35 GB | 多 GPU 配置 (例如,NVIDIA RTX 4090 x2) |
- 我们直接选择 7B 这个模型,然后右边有一个对应的命令,我们直接复制
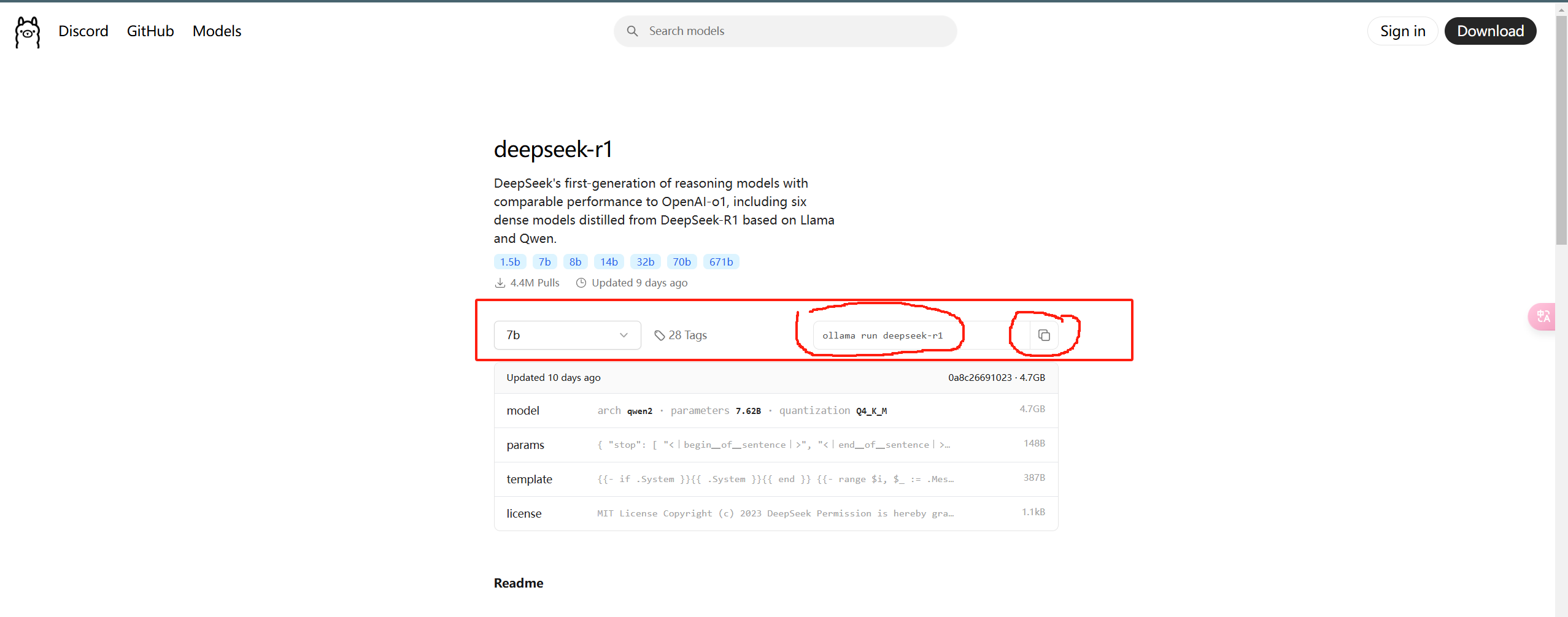
- 回到我们的命令模式,我们直接 win+R 输入 cmd 调出命令行进入到命令模式,然后粘贴我们刚刚复制的命令
- 等待片刻进行下载就行了,这里的话我等了一上午才下好的,有点小慢说实话,这个下载的话好像默认是在 c 盘里面下载的,如果你想在 D 盘下载的话你去 D 盘创建一个仓库,如果当你看到这里的话已经下好了的话,那么你可以等这个下载完成之后输入命令进行卸载操作,然后再去 D 盘仓库打开命令模式再进行安装就会直接在你的 D 盘进行下载了,这个卸载的命令的话后面会说的哈
- 如果你的下载速度很慢的话,你可以 CTRL+C 先退出这个命令,然后再输入命令重新进行下载,还是会从上次的下载进度继续下载的,我这里重新下载了,可以发现速度快了些了
- 我这里也是重复下载了很多遍了,因为这个网速时快时慢,很难受
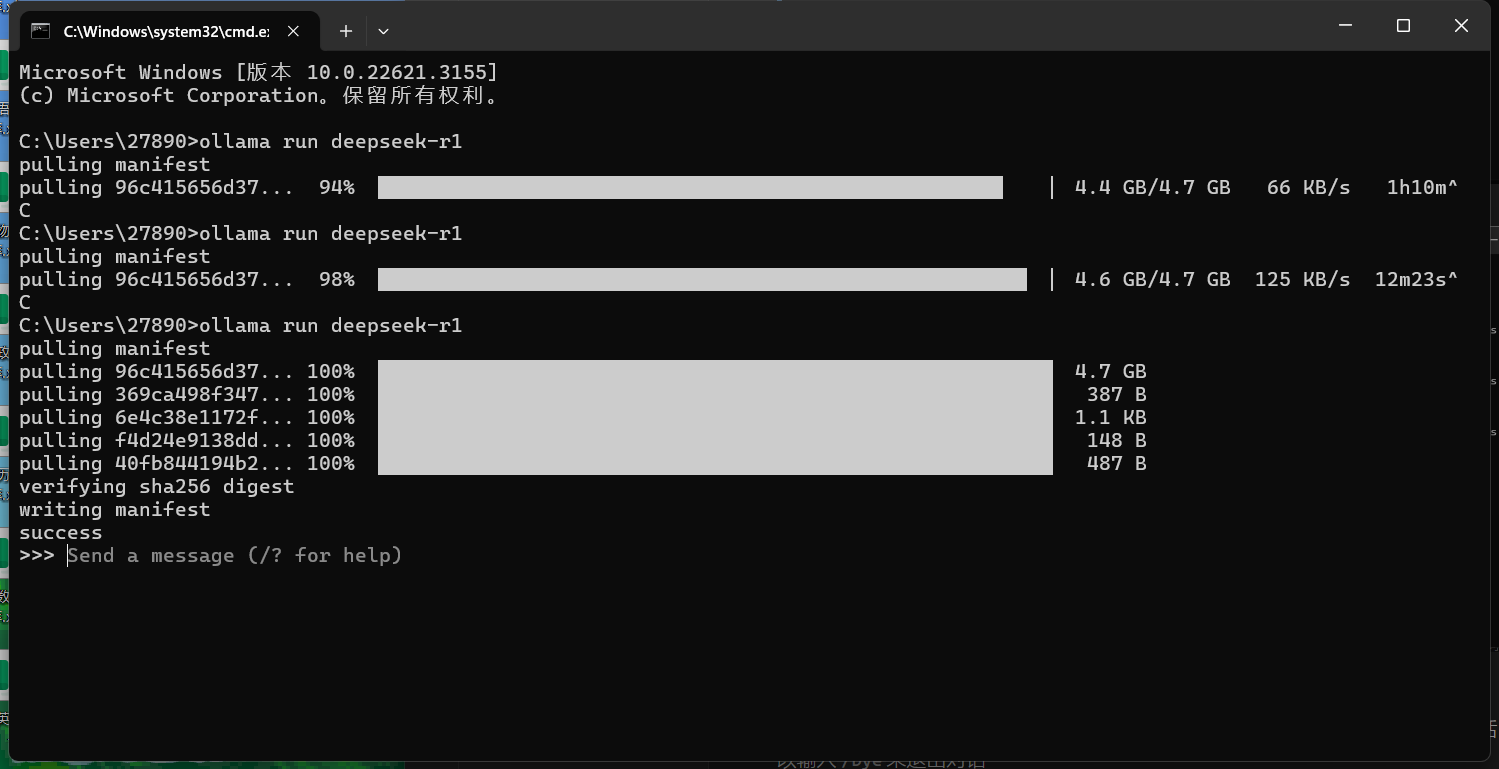
- 这里的话我们就下载好了,出现了一个 success,那么我们就可以直接进行对话了,如果想退出对话的话,我们可以输入
/bye来退出对话
- 这里我们让他帮我们写一个冒泡排序,可以发现很智能嘞,我们可以输入命令
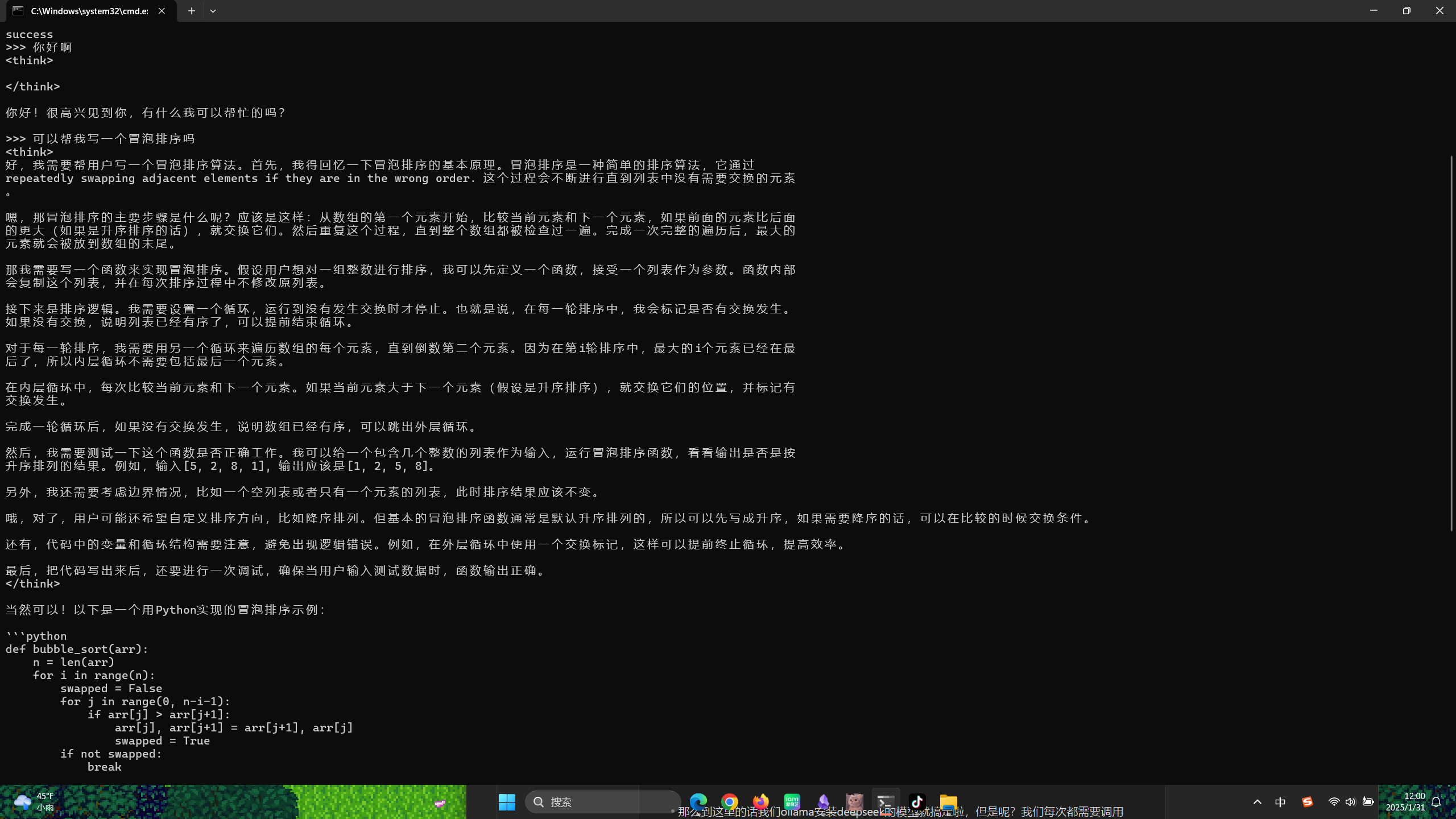

- 但是我们现在想重新进入到对话的话,我们可以输入命令
ollama list重新查看我们已经下载好了的模型,那么我们可以发现这里的 R1 7B 是我们刚刚下载好的模型

- 我们将这个模型的名字复制下来,然后回到命令行输入
ollama run deepseek-r1:latest我们就能重新进入到对话了,这里我们简单进行对话下,可以发现效果还是挺 ok 的

- 那么到这里的话我们 ollama 安装 deepseek 的模型就搞定啦,但是呢?我们每次都需要调用命令行就很不方便,那么我们能不能搞一个聊天的界面,和 QQ 微信一样呢?这里我的回答是可以的,这个就是在可视化的界面使用本地的模型
- 这里我们教你们如何卸载我们本地的模型
- 我们这里的话输入了
olloma list可以看到我们下载的模型,然后将我们的 R1 模型名称进行复制,然后输入命令ollama rm deepseek-r1:latest然后就可以将我们本地的删除了

安装 chatbox
- 我们打开 chat 的官网进行下载操作,我们直接点击免费下载就行了,当然了你如果不想下载的话可以私信我哦,我直接发你这样更快
- 我们双击安装包,点击下一步
- 选择好我们对应的文件夹进行安装操作,安装目录的话我们可以自行进行设置,尽量放在 D 盘,不要放在 C 盘
- 这里我们安装好了之后我们运行这个软件,我们选择这个使用自己的 API Key 或本地模型
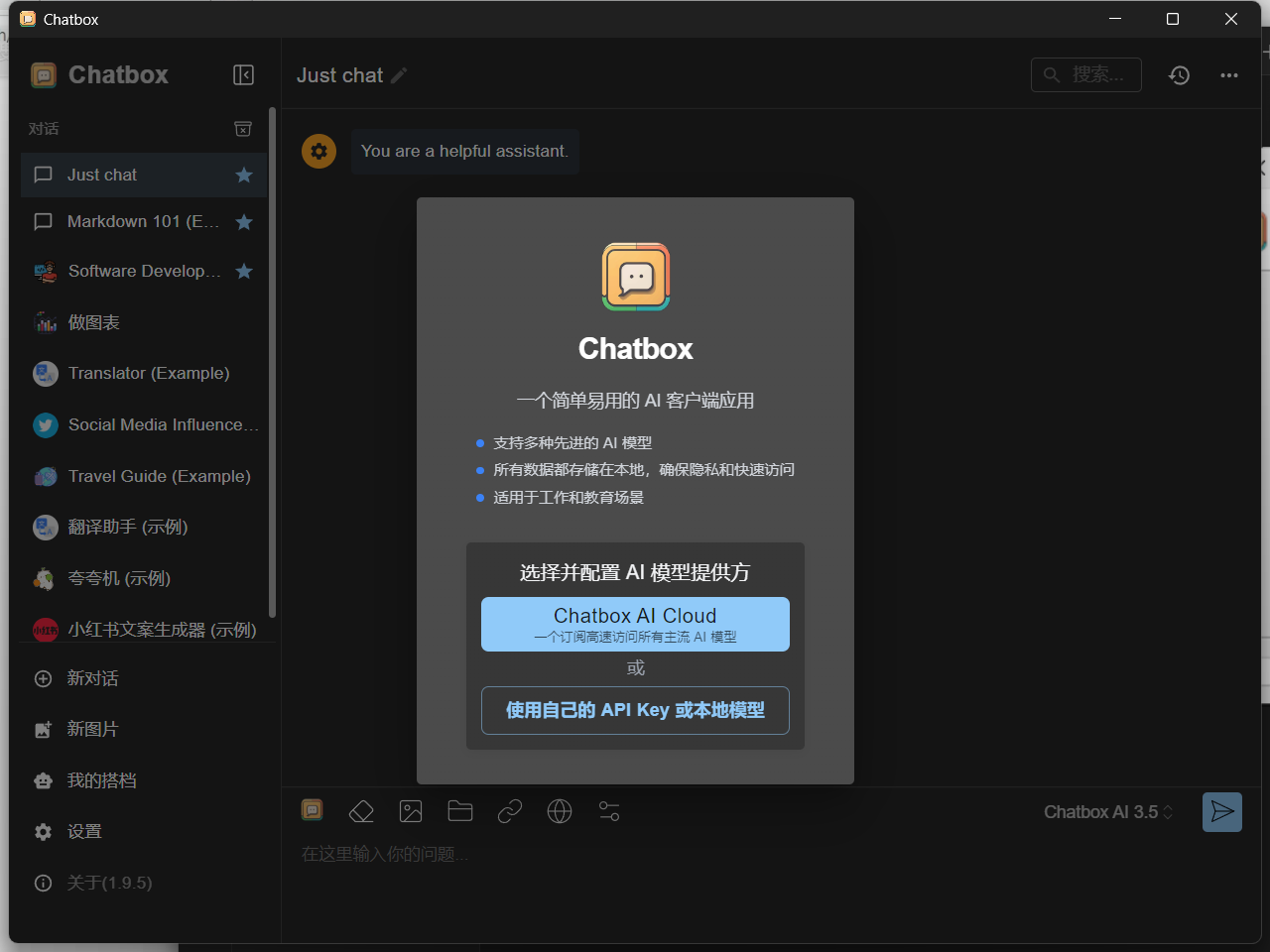
- 选择这个 chatbox AI
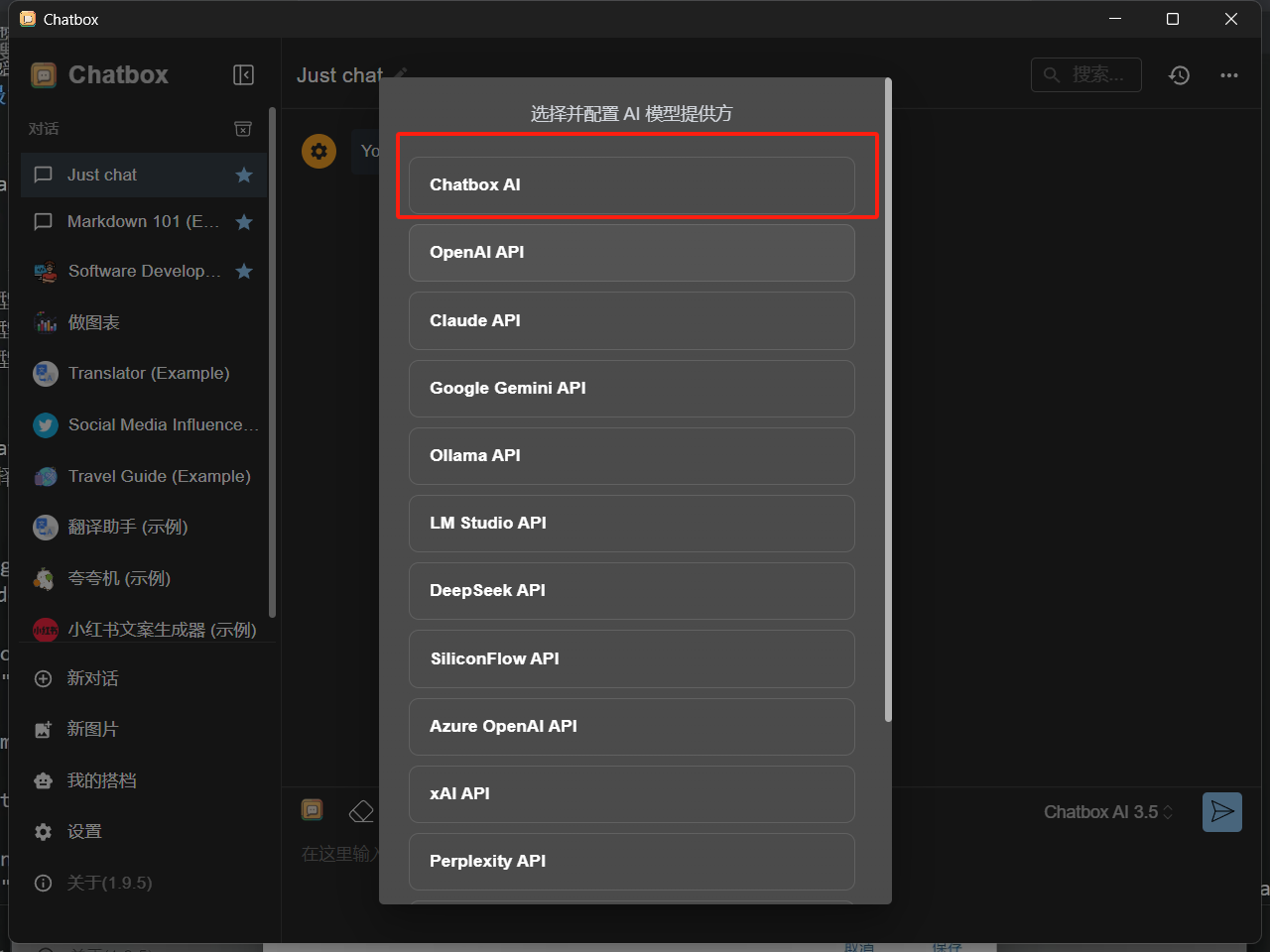
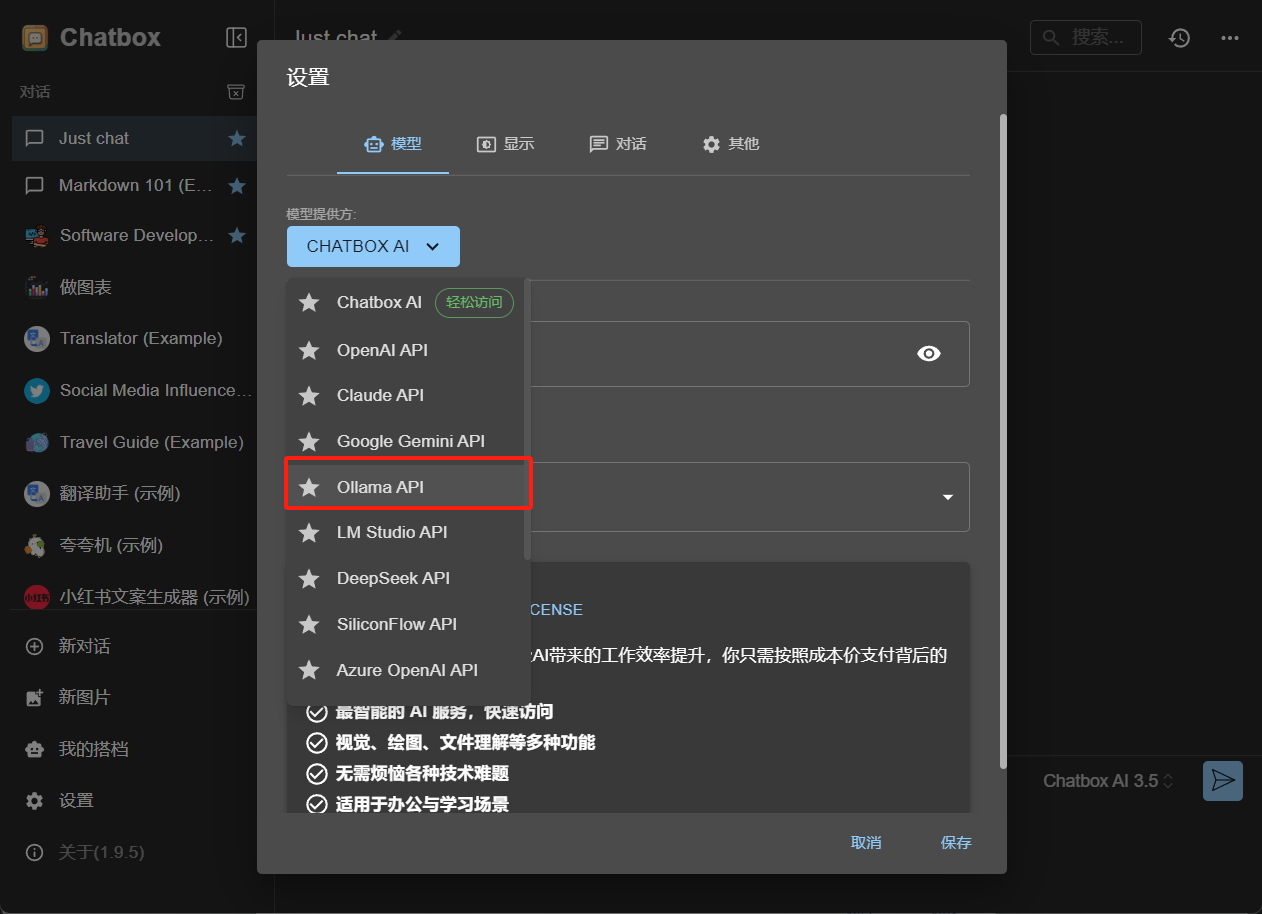
- 我们在模型设置这里选择 Ollama API,然后这个域名的话我们是可以不用改的
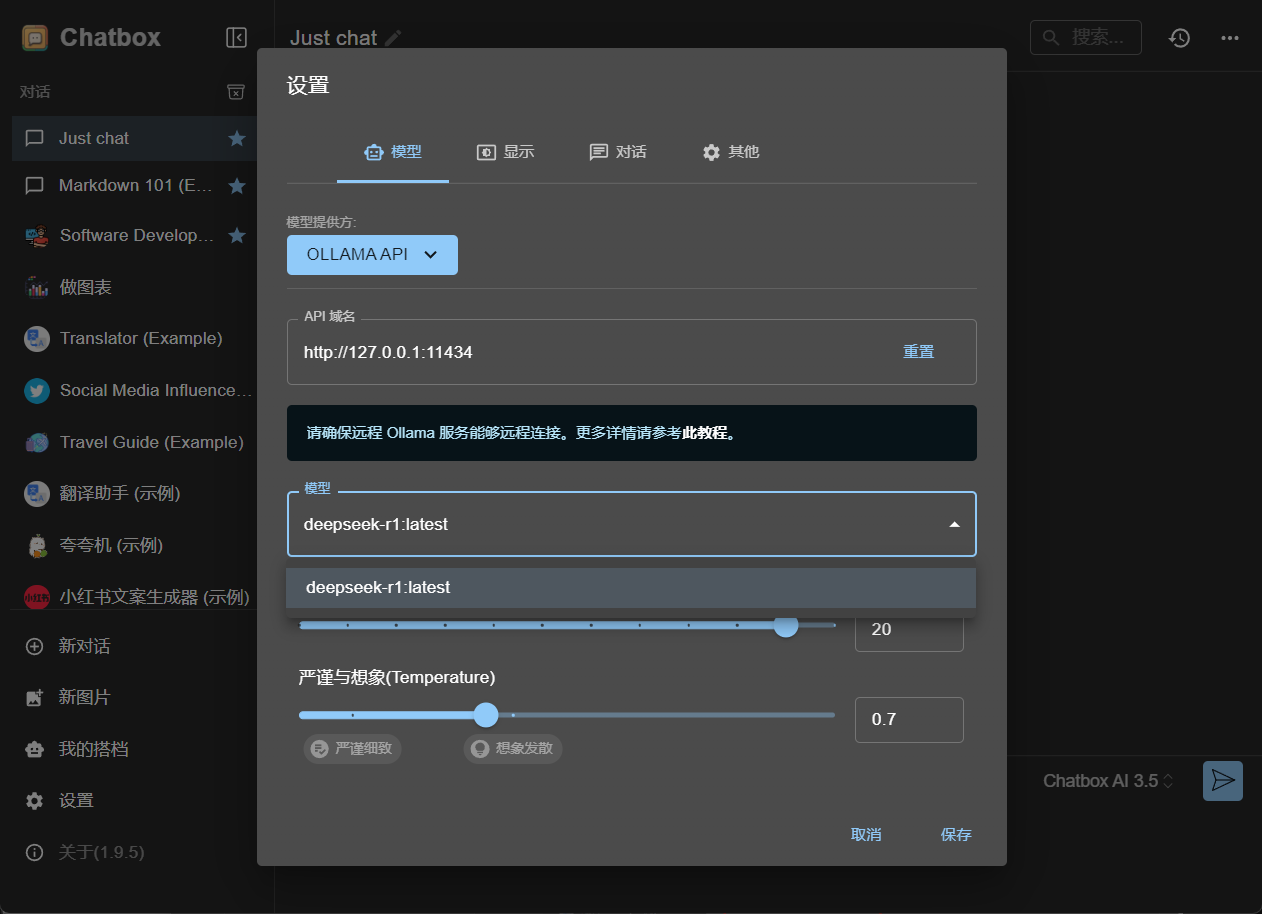
- 然后这个模型这里就会显示我们上面下载好了的 deepseek 的模型,然后保存就行了
- 然后我们就可以在这个可视化的界面进行聊天了,可以发现反应的速度很快,回答的话也很智能,那么到这里的话我们本地部署的 R1 就可以使用了
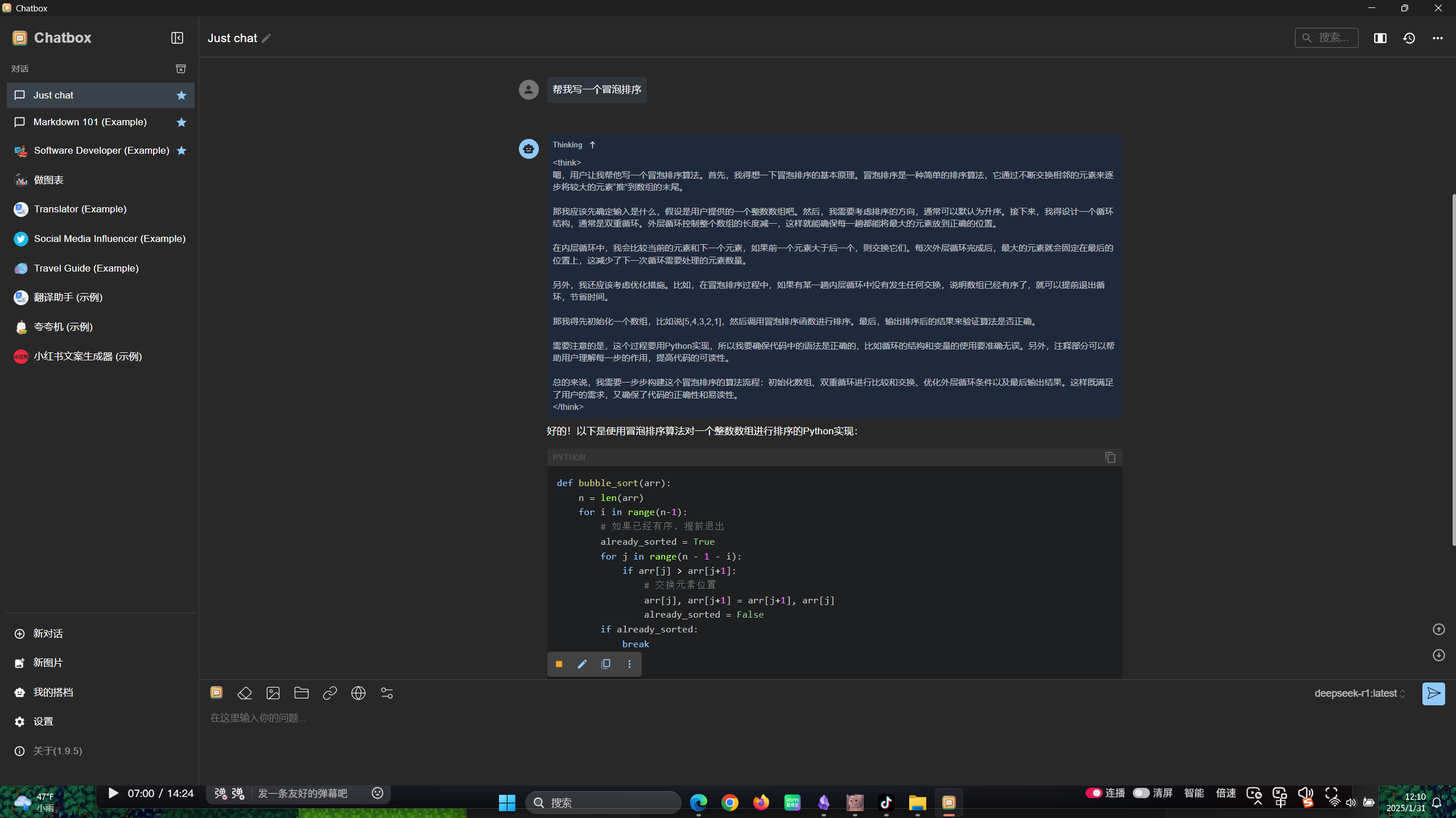
好的!以下是使用冒泡排序算法对一个整数数组进行排序的 Python 实现:
def bubble_sort(arr):
n = len(arr)
for i in range(n-1):
# 如果已经有序,提前退出
already_sorted = True
for j in range(n - 1 - i):
if arr[j] > arr[j+1]:
# 交换元素位置
arr[j], arr[j+1] = arr[j+1], arr[j]
already_sorted = False
if already_sorted:
break
# 示例数组
arr = [5, 4, 3, 2, 1]
bubble_sort(arr)
print("排序后:", arr)
代码解释:
- 函数定义:
bubble_sort(arr)接受一个整数数组arr作为输入。 - 外层循环:
for i in range(n-1),其中n是数组的长度。这个循环控制整个数组的大致范围。 - 提前退出优化:
already_sorted = True,如果在某一趟排序中没有发生交换,则说明数组已经有序,提前退出。 - 内层循环:
for j in range(n - 1 - i),用于比较相邻的元素,并进行交换。 - 交换条件:
if arr[j] > arr[j+1],如果当前元素大于下一个元素,则交换它们的位置。 - 示例数组:
arr = [5, 4, 3, 2, 1],用于测试排序算法。 - 调用函数并打印结果:对数组
arr调用bubble_sort()函数,并打印排序后的结果。
运行这段代码后,输出将是:
排序后: [1, 2, 3, 4, 5]冒泡排序的时间复杂度为 O(n²),适用于小规模数据的排序。
这里其实是可以自定义模型的,但是这里我就不过多进行叙述了,因为我们上面这个就够用了。 这个自定义的话就是你让这个 deepseek 带入一个角色,你让他是一个医生,然后他就会以医生的视角回答你所询问的问题
那么在平常的代码问题,我们对可以询问我们本地部署的这个 deepseek,十分方便呢
感觉这个 deepseek 的话对图片的分析还是差点意思
 Google Chrome
Google Chrome  Windows 10
Windows 10